Документация Сотбит: Парсер контента. Для пользователя. Руководство по селекторам
Руководство по селекторам
Для настройки парсера используются различные селекторы контента. Неподготовленный пользователь боится незнакомого словосочетания, но на практике всё довольно просто.
Каждая страница или файл имеет свою структуру, по которой браузер строит страницу. В этой структуре у каждого элемента есть свой адрес. Селектор - это правило, по которому можно выделить нужный элемент. Они простые и быстро осваиваются.
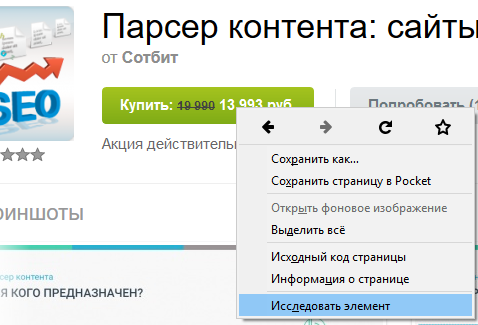
Посмотреть код любого элемента на странице можно при помощи браузера. Достаточно кликнуть правой кнопкой мыши по элементу и выбрать соответствующий пункт. В разных версиях браузеров они имеют своё название, но общий смысл всегда одинаковый. Пример из браузера Firefox версии 55:
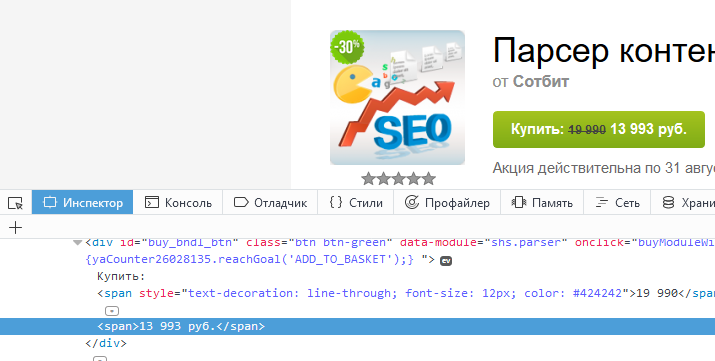
После нажатия на "Исследовать элемент" откроется консоль разработчика, где отобразится исходный код страницы, а элемент будет выделен:
Так можно быстро подсмотреть код любого элемента на любой странице. Цена, ссылка, картинка — всё это доступно по правому клику по элементу. Живой пример можно найти в любом из наших роликов по настройке парсера.
Любая HTML-страничка состоит из элементов (div, span, br, p, table и т.п.), которые могут иметь классы (class="класс1 класс2"), идентификаторы (id="buy_btn") и другие атрибуты (title="заголовок"). Каждый элемент может быть вложен в другой элемент. Селектор нам помогает в этом ориентироваться.
В большинстве ситуаций достаточно самых простых селекторов:
#id — для элементов по их уникальному идентификатору.
element — для элементов по названию элемента
.class — для выбора элементов по классу
[attribute] — для атрибутов
* — для выбора всех элементов
Селекторы могут сочетаться друг с другом. Все они пишутся слитно. Пробел означает вложенность. Читать такую конструкцию удобно справа налево. Например:
#tovar — выберет элемент, у которого идентификатор равен tovar. Например, <a id="tovar"> подойдёт .
#tovar a.nash — выберет все элементы a, с классом class="nash", которые лежат внутри элемента, у которого id="tovar".
table.catalog.content .odd.item span — выберет все элементы span, которые лежат внутри любых элементов, у которых одновременно есть классы odd и item (Например,class="odd type5-par item item-tovar"), которые находятся внутри таблицы с классами catalog и content.
Рассмотрим на реальном примере:
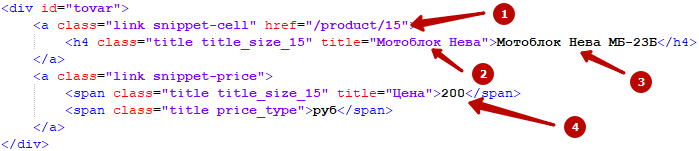
Подберём селекторы для четырёх обозначенных значений товара, а также сам селектор товара.
Для каждой страницы id элементов должны быть уникальны, потому селектор товара на странице нашли, это будет #tovar. Где-то на странице может быть много других элементов div, но div#tovar только один.
Ссылка на товар хранится в элементе a, в его атрибуте href. Элементов a на странице несколько, поэтому нужно найти уникальный признак. В нашем случае есть несколько вариантов. Можно указать уникальный класс. link не подходит, он не уникален. Пишем оставшийся, получается селектор a.snippet-cell[href]. Парсер найдёт внутри div два разных элемента a, выберет единственный с классом snippet-cell, а из него уже заберёт значение атрибута href. В поле запишется "/product/15".
Искомое название выделить очень легко, у нас только один элемент h4. Пишем h4[title]. В поле попадёт значение "Мотоблок Нева".
Опять простой вариант, значение хранится внутри уникального тега. Пишем h4. В поле попадёт значение "Мотоблок Нева МБ-23Б".
Здесь можно привязаться к сочетанию элемента и класса, можно к его порядку. Подходящий селектор span.title_size_15. В поле попадёт значение "200".
Ситуация может оказаться гораздо сложнее. Число элементов может меняться, у них может не быть уникальных классов, их может быть сложно выделить из остальных. В таких случаях помогают более продвинутые селекторы:
:not(селектор) — для элементов, не содержащих селектор. :eq(число) — для выбора элемента по порядку. Начинается с нуля. :eq(0) выберет первый элемент, :eq(1) выделит второй, :eq(7) отметит только шестой и т.д. :last — для последнего элемента.
На примере с мотоблоками можно было не привязываться к классам и написать селекторы иначе:
a:eq(0)[href] — данные получим из атрибута href первой ссылки.
h4[title]
h4
span:eq(0) — данные берём из первого элемента span.
Для более сложных ситуаций есть селекторы иерархии, содержимого и много других. Полный список можно увидеть на странице руководства по phpquery. Однако не стоит сразу пытаться соорудить очень сложный селектор. Часто значения дублируются на превью и детальной странице товара, выбирайте самый простой вариант (по id, если его нет, то по классам и т.д)
Если селектор товара указывает на элемент a, являющийся ссылкой, то селектор ссылки для такого товара будет a:parent
Проверить селектор часто можно без запуска парсера. Для этого нужно открыть страницу, активировать консоль разработчика (F12), переключиться на вкладку "Консоль", а там ввести селектор в виде $('селектор') и нажать ввод. Если на странице подключен скрипт JQuery, браузер отобразит подходящий под селектор элемент:
Для других форматов файлов существуют свои структурные особенности, однако общие принципы неизменны. Везде есть элементы и атрибуты, а для парсера нужно просто указать уникальный к ним путь.
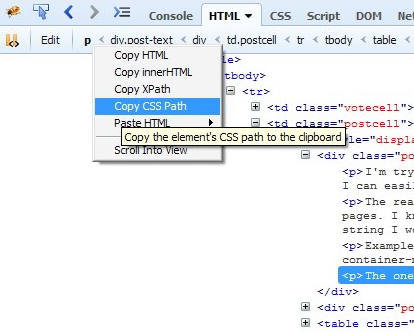
Путь может подсказать и сам браузер, для этого нужно открыть консоль разработчика, нажать правой кнопкой по элементу и выбрать "копировать -> путь CSS":